Halloween Hijinks: Huffman-Coded Audio

For our Halloween project this year we decided to do a nerdy take on a classic prank: scaring trick-or-treaters. This project uses a magnetic reed switch, a NerdKit, and set of computer speakers to frighten unsuspecting visitors at the door. In covering constructing this project, we get a chance to go over some pretty neat engineering concepts: digital audio, data compression using Huffman codes, and outputing audio via PWM with analog filtering.
Click any photo to enlarge:





Magnetic Reed Switch
To detect whether the door was opened or closed, we used a magnetic reed switch, like the kind used in wired alarm systems. This one from Amazon.com illustrates the basic concept. One part has a magnet, and would be mounted on the moving door or window. The other part has a magnetic-field-sensitive switch, and this one has three screw terminals for the switch contacts.

For the switch we purchased, we wired the "COM" common terminal to ground on our breadboard, and connected the "NC" normally closed terminal to our microcontroller pin PC5 (ATmega328P pin #28). For our part, this meant that the switch was closed (connected) when the magnet was nearby. As we discussed in our Digital Calipers DRO video, we can use the microcontroller's built-in pull-up resistors to easily read from a switch or button with no extra components.
Huffman Coding
As explained in the video, for variable-length codes, we generate a tree of binary ones and zeros corresponding to a sequence of bits, and each "leaf" of the tree corresponds to a symbol being output from the decoder. By visualizing this as a tree, we automatically enforce the constraint that no complete code for a symbol is the contained within the beginning of the code for a different symbol.
Huffman coding is the specific way to generate this tree in an optimal way. By optimal, we mean that if we know ahead of time the probability distribution of all of the different symbols occuring in our information stream (and assume them to be independent), we construct the code that minimizes the expected number of bits needed to transmit a symbol. Of course, if our probability distribution ends up being far from what we expected, our Huffman code will not perform well, and in fact may even be worse than just assuming equal probabilities of all signals (which is essentially what ASCII and other fixed-length encodings do).
(Side note: as we mentioned, Huffman coding doesn't do anything to "compress" the fact that adjacent symbols might have probability distributions that depend on each other. For example, in English, the letter "q" is almost always followed by "u", so if we saw a "q", the probablility of the next symbol being "u" is extremely high. Technically speaking, what we are doing in this project is considered "coding" -- not "compression" -- but it does have the effect of squeezing more symbols into less bits. Other algorithms, like LZW, take advantage of the probabilities of adjacent symbols *not* being independent to achieve great compression, and LZW for example is a key part of many file formats.)
For more on this topic, and how Huffman trees are actually generated, we refer you to the excellent MIT 6.050 Information & Entropy course notes (4.4MB PDF). Pages 66-68 of thid document specifically talk about "Efficient Source Codes" and the Huffman Code in particular. However, chapters 2, 3, and 4 will also likely be of interest to those curious about this topic. The video lectures from this course may also be of interest.
Implementing the Coding & Decoding
Using a series of Python scripts, we transform a sound file into a C header file for inclusion in our program. These scripts also build a C function that implements the decoder for our Huffman tree. You can grab the source code in our "Source Code" section below, but for now, we're just going to provide a high level overview of the process. We'll look at one particular sound sample -- the "evil laugh" recording. We intentionally used verbose, human-readable intermediate formats to help make this an illustrative code sample.
First, we start with a WAV file (16-bit, mono channel): evil_laugh.wav.
Now, our encoder_p1.py script opens the WAV file, truncates each 16-bit sample down to be 8 bits wide, and takes the first difference. This list of symbols are now output as evil_laugh.symbols.
After this encoder_p1.py process is run on all of the sound files, we next run huffmancode_exp.py, which examines all of the symbols and how often they occur, and determines which bit sequence to assign to each symbol based on these probabilities. This outputs a file huffmancode.txt. This shows each symbol along with its pattern of 0s and 1s. The bottom lines of the file also contain two comments, "Theoretical entropy: 4.84904206978 bits per symbol" and "Huffman code avg.len: 4.88124184353 bits per symbol". That means that the encoder recognizes that based on the probability distribution, there are only 4.85 bits of true "information" per symbol. Our ability to compress is based on the fact that 4.85 is much less than 8 bits. And our Huffman code achieves an expected 4.88 bits per symbol -- quite close to the 4.85!
Now that we have our Huffman tree, we send the huffmancode.txt file into our huffman_to_c_3.py script, and this generates the decoder C code huffcode.c. We did experiment with other ways to store our Huffman tree -- for example, specifically storing a table in Flash and making it iterate over that table. However, the only implementation that would run fast enough on our microcontroller was to simply encode the decoder as a C function with a big nest of if/else branches!
Now, we've got to encode our symbols lists as bitstrings. We do this with our encoder_p2.py script, which reads in huffmancode.txt as well as evil_laugh.symbols, and generates evil_laugh.bitstring (note: unreadable binary file) and evil_laugh.bitstrings.samples. This contains the packed binary data we want to store on the chip.
Finally, we use our bitstring_to_c.py script to produce a C header file that we can actually compile right into our code. It reads in evil_laugh.bitstring and evil_laugh.bitstrings.samples and generates a perfectly readable evil_laugh.h file which contains the sound data and a little bit of metadata. And that's it! We can then just do an "#include <evil_laugh.h>" from our main C code.
PWM Audio and Filtering
The output of our microcontroller is purely digital, but our speaker amplifier needs an analog input. In previous videos, we've explored pulse width modulation (PWM), showing how to use PWM to control LED brightness, how to use PWM to control a hobby servo, and how to use PWM to control the speed of a motor. However, audio output introduces additional challenges because the human ability to hear sounds goes to much higher frequencies (~20,000 Hz) than the optical or mechanical systems discussed before (perhaps ~20 Hz). This means that unless we take the proper design considerations, we might actually hear the on-off switching of our PWM output, rather than the smoothed, average value like we saw in the earlier examples.
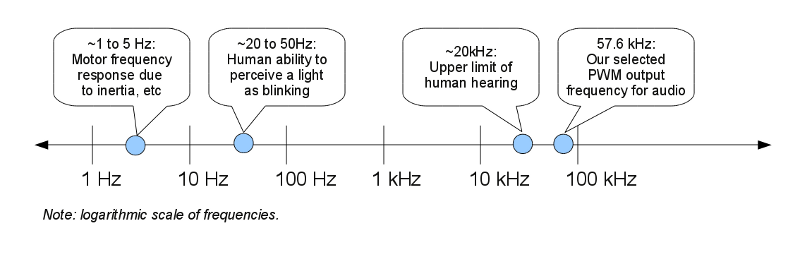
There are two important things we can do. The first is to make the PWM frequency as fast as we can reasonably handle in our code. By making the frequency higher, the switching happens more frequently, so the average value becomes apparent over shorter timescales. This means that at some point, some limiting factors, like our human auditory perception, or the response of the speaker cone, will limit our ability to perceive the PWM switching.
We decided to run our PWM from the main microcontroller clock (14.7456 MHz), using 8-bit "Fast PWM" mode. This means that there's a counter counting from 0 to 255, and then starting at 0 again. At each cycle, the microcontroller's hardware PWM module compares our setting to the counter, and decides whether to turn the input pin on or off, producing the correct PWM duty cycle. Our overall PWM frequency will be (14745600 Hz)/(256 cycles / PWM loop) = 57600 PWM loops per second. That's about a factor of three higher than the upper range of human auditory hearing, so simply making the design decision to place the PWM frequency this high will greatly alleviate audible PWM switching noise.
Side note: our audio is recorded at 8000 samples/second, but we have 57600 PWM loops per second. For simplicity, we decided to play each audio sample for 7 PWM loops before switching to the next sample. This means that we're actually playing our audio a little bit (3%) faster than it was designed to at about 8229 samples/second, which might be an issue if we were playing music in a precise key.
Placing the PWM frequency as high as possible is a great start, but the second thing we need to do is to provide an analog low-pass filter to actually squelch the high frequency component of the signal before it ever gets to the audio amplifier. We implemented this with a RC low-pass filter, consisting of a 680 ohm resistor and a 0.1µF capacitor. This puts a corner frequency at:
f-3db = 1 / (2π × 680 × 0.1×10-6) = 2341 Hz
Thanks to the math of first-order systems, we can approximate how much of the switching noise gets through this filter. With the corner at 2341 Hz, and the PWM frequency at 57600 Hz (and multiples thereof, since a square wave has an infinite number of harmonics), the fundamental is reduced to be approximately 2341/57600 = about 4% of its original amplitude. The higher harmonics are reduced even more. That's not nothing, and true audiophiles might still complain, but the result in this project was quite sufficient.
Here's the schematic of our filter:
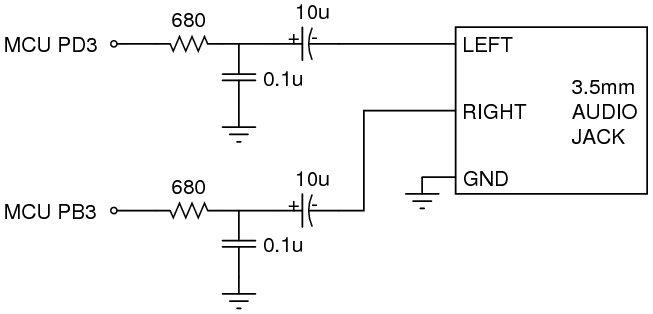
And here's what it looks like on the breadboard:

The 10 microfarad capacitor in series with each audio output lets us use our 2.5V-centered microcontroller output but still talk to a 0V-centered audio line in. It's generally considered bad form to have a DC offset going into a speaker or audio amplifier because, depending on how the device itself is implemented, it can cause problems either with overheating or with non-linear effects like saturation. The 10µF capacitor is large enough that it looks like a short circuit to audio frequencies -- it doesn't substantially charge or discharge during an audio waveform, so the voltage wiggle on one side gets copied to the other side. However, at DC, it looks like an open circuit, so no DC current is allowed to pass. Check out our Piezoelectric Sound Meter video tutorial for another case where we talk about how capacitors work at different frequencies. In this case, a typical audio line-in will look like it's a 1K to 10K ohm resistive load. If it's 10K, then with our 10µF capacitor, we'd have a high-pass filter with a corner frequency at:
f-3db = 1 / (2π × 10000 × 10×10-6) = 1.6 Hz
This indicates that frequencies roughly in the 2 to 2300 Hz range will pass through from our PWM output to our audio line-in, while frequencies substantially out of that range will not -- the will be "attenuated".
We can use circuit simulation software to construct the filter as well as the input impedance of the audio amplifier. This can then tell us how large an output signal we get for different frequencies of input signals:
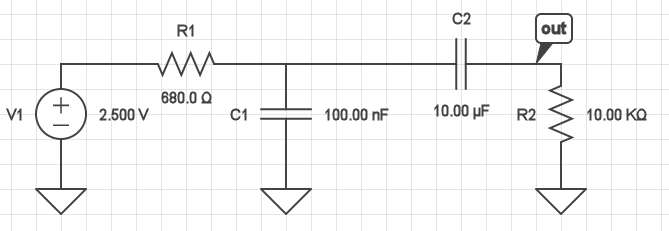
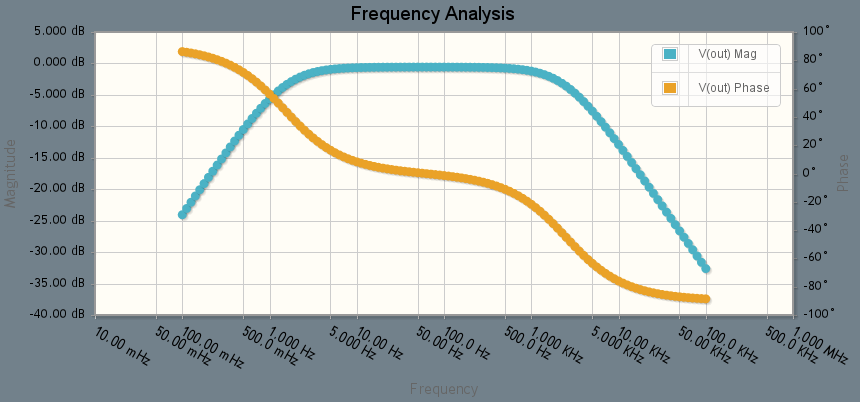
The blue line in the graph above shows a plot of magnitude (in decibels) versus frequency (on a logarithmic scale). In the middle band of frequencies (roughly 2 to 2000 Hz), the magnitude graph is at about -0.6dB, which is a voltage magnitude of 10-0.6/20=0.93. That means that a signal in that frequency range will get through with roughly 93% of its original amplitude. In contrast, at frequencies outside that band, the signal will be attenuated. For example, the graph hits -20dB at approximately 0.16 Hz and again at about 25 kHz. At these two points, the voltage waveform is reduced by the filter to be just 10-20/20 = 0.1 = 10% of its input magnitude.
Parts List
In addition to one USB NerdKit, the following extra parts are needed to complete this project:
Source Code
You can download a ZIP file containing the source code (including both the microcontroller C code as well as the Python scripts involved in performing the Huffman encoding of the audio) here.
More Videos and Projects!
Take a look at more videos and microcontroller projects!
Comments
|
Did you know that multiple microcontrollers can communicate with each other? Learn more...
|


Copyright © 2013 by NerdKits, L.L.C.